hai
Co-Authored with AI

I am not a programmer. I have spent years operating Linux and Kubernetes infrastructure, but I cannot write production code on my own to a quality I’d feel comfortable shipping to a maintainer. What changed in the last year is that I can ship code anyway: Claude Code writes what I cannot, I keep ownership of the judgment calls, and we end up with contributions real maintainers actually act on.
This page is a running log of upstream OSS contributions (bug fixes, new features, and bug reports too detailed to ignore) where, without Claude Code, I would not have filed it at all. Either I would not have found the bug, traced it to the right code path, designed the feature, written the code, written the tests, read the upstream’s lint config, or some combination of those.
The human side
The code is the visible part of this, but what’s actually stayed with me are the conversations. Every contribution has ended up being a doorway to the human behind the project, and I’ve made real friends along the way: Stefan Prodan (Flux), Gianluca Mardente (k8s-cleaner), Lukas Hankeln (renovate-operator), and others who’ve been generous with their time and always up for the next idea. I’d been following Viktor Farcic (dot-ai) for years; these PRs finally gave me a reason to reach out on Slack and actually talk. In a world that’s starting to feel fully automated, these conversations are the part I want to hold onto.
My workflow
For every bug fix or new feature below, I follow the same loop, captured in a private upstream-fork skill:
- Open an issue on my own tracker and draft a PRD so I have a clear target before writing a line of code.
- Fork the upstream repo and develop the change on a branch.
- Run multi-agent code review with separate Claude subagents (QA, coding standards, code/logic) against the diff.
- Build and deploy the fork image to my cluster (when applicable) and validate end-to-end against my real workload.
- Open the upstream PR once I’ve convinced myself it actually works under load.
I usually let maintainers know in private, or include something like this in the PR body:
Full disclosure: I don’t have any programming skills so I asked Claude Code to implement this and did my best to test it and not create AI slop.
Contributions
Features
k8s-cleaner #556: Embedded web dashboard for scan results and on-demand triggers
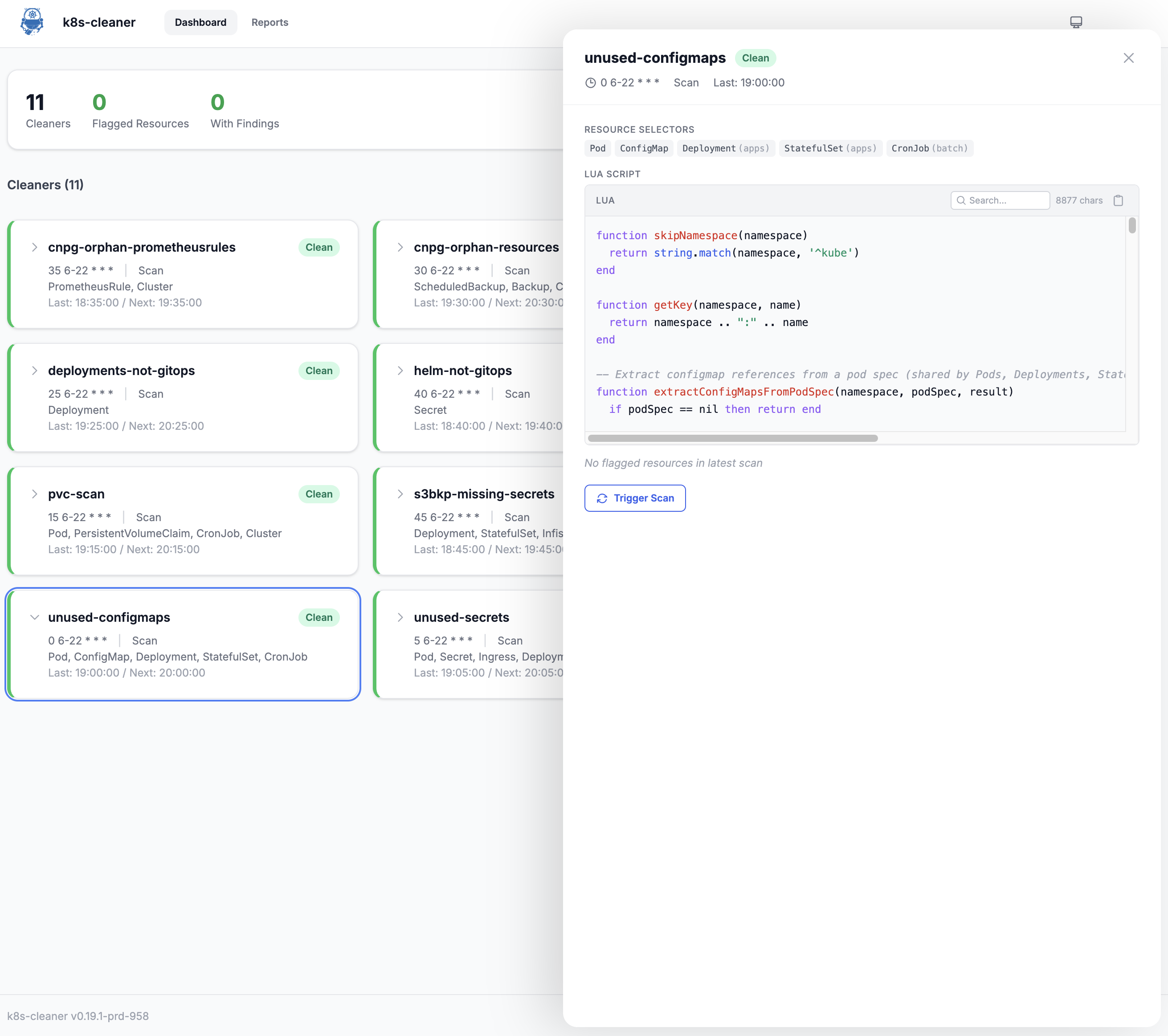
- Project: gianlucam76/k8s-cleaner (Kubernetes operator that uses Lua scripts to identify orphaned/unused resources)
- PR: gianlucam76/k8s-cleaner#556
- Status: merged 2026-04-05
- Language: Go + Preact
Added an embedded web dashboard behind a --enable-web flag, served by a Go HTTP server with a Preact + Tailwind SPA bundled into the binary via embed.FS (89KB total). The dashboard exposes a REST API at /api/v1/ and lets you browse scan results, view the Lua scripts each cleaner runs, and trigger on-demand scans without kubectl access. Includes a read-only mode middleware, Helm chart values for all the new flags, and 24 new tests (16 Go handler tests + 8 Vitest UI component tests). Zero changes to the existing controller, API, or pkg/; all new code in internal/web/ and web/.
renovate-operator #239: PR activity per run in the operator UI
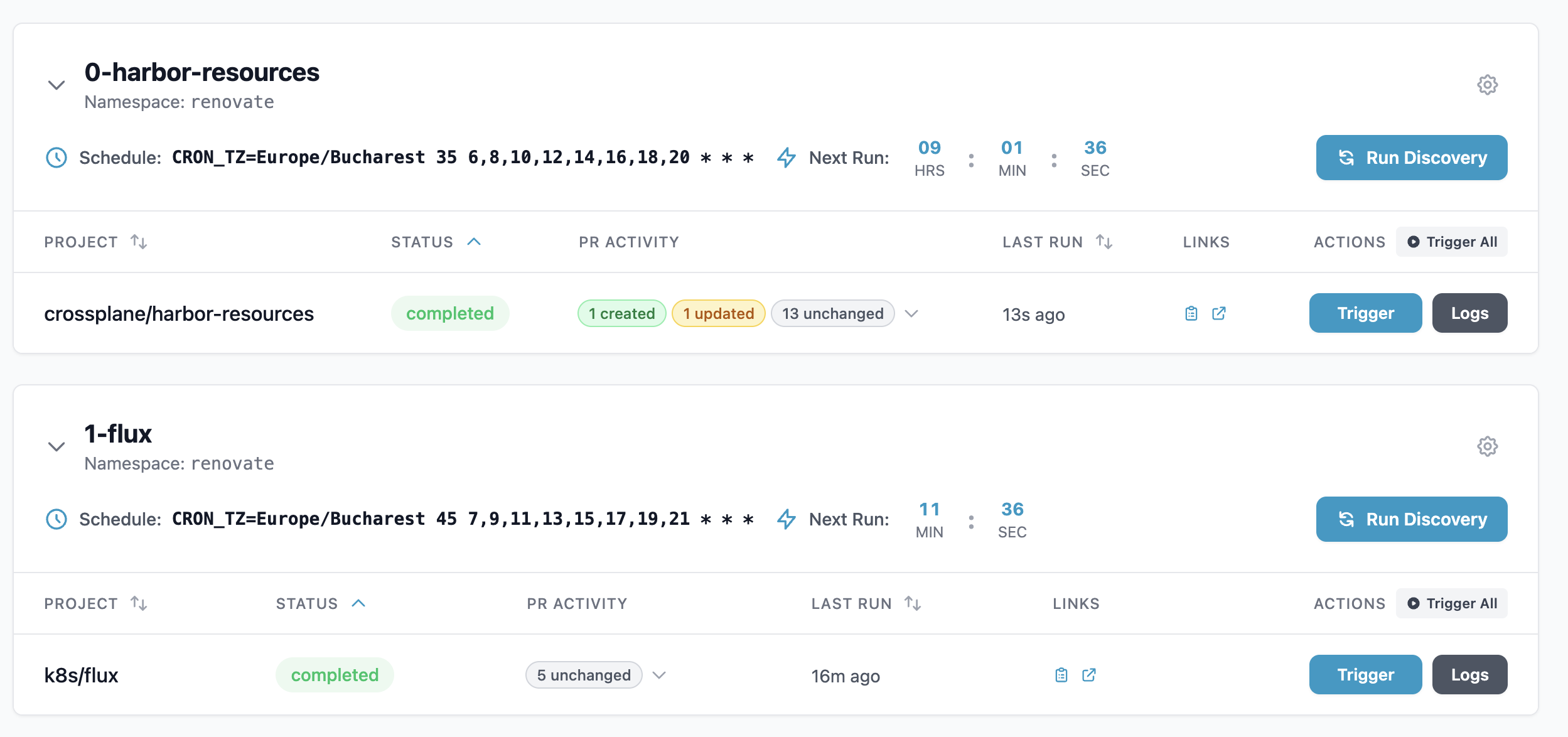
- Project: mogenius/renovate-operator (Kubernetes operator for Renovate)
- PR: mogenius/renovate-operator#239
- Status: merged 2026-04-02
- Language: Go + UI
Extended the Renovate log parser to detect 7 message types and extract per-PR activity (created, updated, unchanged, automerged) from the JSON logs of each Renovate run, then surfaced it in the operator dashboard with expandable accordion rows showing per-PR details and clickable links back to the forge. Added new CRD types (PRAction, PRDetail, PRActivity), a per-project status update flow, multi-forge URL handling (GitHub, Forgejo, GitLab), 25 new parser test cases, and a bonus deep-copy bugfix for RenovateJobList. Closes upstream issue #115.
Bugs
pocket-id #1413: Custom logos and favicons disappeared after every pod restart
- Project: pocket-id/pocket-id (self-hosted OIDC provider)
- PR: pocket-id/pocket-id#1413
- Issue: pocket-id/pocket-id#1407
- Status: open, waiting for upstream review
- Language: Go
Pocket-ID’s S3 backend returned full prefixed keys from List instead of relative paths, double-prefixing every subsequent Open and silently 404’ing, which made every custom logo and favicon vanish from my homelab after every pod restart. Fixed by stripping the prefix in List with a small pathFromKey helper plus round-trip unit tests.
Issues
Listed in reverse chronological order (most recent first).
Dippy #110: Permit rule with trailing ` *` didn’t match bare commands
- Project: ldayton/Dippy (Claude Code permission/config manager)
- Issue: ldayton/Dippy#110
- Status: fixed by maintainer
- Language: Python
When a Dippy permit rule contains glob characters and ends with ` , the trailing * fallback for bare commands (no args) was using exact string comparison instead of fnmatch(). Patterns like ask tea issue close * matched tea issues close 42 but failed to match the bare tea issues close`, because the fallback expected the exact pattern string, not a glob match.
ghostty #1524: Hue-preserving minimum-contrast in the Metal shader
- Project: ghostty-org/ghostty (cross-platform terminal emulator)
- Issue: ghostty-org/ghostty#1524
- Fork branch: vtmocanu:ghostty:feature/hue-preserving-minimum-contrast
- Status: prototype fork branch shared as a comment on #1524
- Language: Metal shader
Ghostty’s minimum-contrast config snaps foreground colors to pure black or white when the contrast ratio falls below threshold, which destroys Zellij’s bright green on a light theme (it snaps to dark gray, hue lost). This was the sole blocker preventing me from migrating from iTerm2 to Ghostty. Claude Code wrote a hue-preserving fix in the Metal renderer’s shader code; I built and tested it locally on macOS and posted the fork branch on the issue as a starting point for the maintainers.
dot-ai #396: dot-ai 1.6.0 crash-loops when ingress TLS is disabled
- Project: vfarcic/dot-ai (AI-powered Kubernetes operations via MCP)
- Issue: vfarcic/dot-ai#396
- Status: fixed by maintainer
- Language: Helm / TypeScript
Upgrading dot-ai from 1.5.0 to 1.6.0 caused a crash loop whenever ingress.tls.enabled: false. The new Dex sub-chart (enabled by default in chart 0.59.0) derives its DEX_ISSUER_URL from that flag in _helpers.tpl and emits http://... when TLS is off, but Dex rejects non-HTTPS issuer URLs, so startup fails immediately with Issuer URL must be HTTPS.
versitygw #1904: PutObject 501 breaks Nextcloud (x-amz-acl header)
- Project: versity/versitygw (S3-compatible gateway)
- Issue: versity/versitygw#1904
- Status: fixed by maintainer
- Language: Go
When S3 clients send PutObject with the x-amz-acl: private header, VersityGW returns 501 NotImplemented, which breaks Nextcloud (and any other client that hardcodes an ACL on every PUT). The fix is to silently accept private as a no-op since VersityGW’s ACL model is bucket-level anyway; every object is already effectively private.
adguard-exporter #70: /metrics deadlocks from unbounded cardinality in query log metrics
- Project: henrywhitaker3/adguard-exporter (Prometheus exporter for AdGuard Home)
- Issue: henrywhitaker3/adguard-exporter#70
- Status: open
- Language: Go
The /metrics endpoint becomes completely unresponsive after running for a while; even / times out and Prometheus scrapes fail at the 60s mark with zero samples. Traced to collectQueryLogStats() in worker.go creating unique time series per unique combination of 7 labels (server, user, reason, status, upstream, client_name, protocol) without ever resetting them. The metric registry grows unbounded until the exporter grinds to a halt.
rustfs #1838: x86_64 image SIGILLs on CPUs without AVX (Celeron, Atom)
- Project: rustfs/rustfs (Rust-based S3-compatible object storage)
- Issue: rustfs/rustfs#1838
- Status: fixed by maintainer
- Language: Rust
The rustfs/rustfs Docker image (and pre-built x86_64 binaries) crashes immediately with exit 132 (SIGILL: Illegal Instruction) on x86 CPUs that lack AVX/AVX2, such as the Intel Celeron J4125 in my Synology DS920+. The binary had been compiled with AVX-requiring instructions but without runtime CPU feature detection, so it SIGILLs on the first such instruction before main() even runs.
renovate-operator #114: UI showed every repo as not onboarded
- Project: mogenius/renovate-operator (Kubernetes operator for Renovate)
- Issue: mogenius/renovate-operator#114
- Status: fixed by maintainers in v2.4.1
- Language: Go
The Renovate Operator UI was showing “No Config (renovate not onboarded)” for every repo despite all of them being fully onboarded. The log parser was using a naive strings.Contains("onboarding") that matched debug messages like checkOnboarding() present in every run, falsely reporting all repos as un-onboarded.
renovate-operator #117: Onboarding detection still broken after the v2.4.1 fix
- Project: mogenius/renovate-operator (Kubernetes operator for Renovate)
- Issue: mogenius/renovate-operator#117
- Status: issue filed with Go reproducer
- Language: Go
After the v2.4.1 fix landed, large repos still showed as un-onboarded. The cause: Renovate emits a "packageFiles with updates" line that can be 190KB+, while Go’s bufio.Scanner silently stops at 64KB, so the parser never reached the “Repository finished” marker at the end of the logs. One-line fix: scanner.Buffer(make([]byte, 0), 1024*1024).
flux-operator #677: Run Job button missing on the workloads page
- Project: controlplaneio-fluxcd/flux-operator (controller for managing Flux CD)
- Issue: controlplaneio-fluxcd/flux-operator#677
- Status: issue filed
- Language: Go
The Flux Operator web UI was hiding the “Run Job” button on workloads despite the user having permission to trigger them. Tracing the full flow (frontend → API → RBAC check → tests) revealed that resource.go was checking workload actions like restart against the wrong API group, and that the test suite was masking the bug with mock data.
dot-ai-controller #42: Infinite reconciliation loop from oversized status updates
- Project: vfarcic/dot-ai-controller (Kubernetes controller for dot-ai)
- Issue: vfarcic/dot-ai-controller#42
- Status: fixed by maintainer
- Language: Go
When ResourceSyncConfig.status grew past etcd’s 3MB Request entity too large limit, the controller entered an infinite reconciliation loop: the status update failed, which immediately triggered a re-reconcile, which immediately failed again, forever. The result was massive CPU usage and log flooding until the status was manually trimmed out of band.
dot-ai #346: Log spam when the embedding API circuit breaker is open
- Project: vfarcic/dot-ai (AI-powered Kubernetes operations via MCP)
- Issue: vfarcic/dot-ai#346
- Status: fixed by maintainer
- Language: TypeScript
When the embedding API’s circuit breaker was open, the MCP server logged a warning for every single resource it tried to sync. With 353+ watched resource types and many resources per type, that’s 130MB+ of logs in minutes, enough to overwhelm Loki with rate-limit errors. Fix: log once when the breaker trips, then suppress subsequent warnings while it stays open.
k8s-cleaner #439: Gauge metrics for current resource counts (not cumulative counters)
- Project: gianlucam76/k8s-cleaner (Kubernetes operator that uses Lua scripts to identify orphaned/unused resources)
- Issue: gianlucam76/k8s-cleaner#439
- Status: fixed by maintainer
- Language: Go
The k8s_cleaner_scan_resources_total metric was a cumulative counter, which made meaningful Prometheus alerts hard. Alerts based on > 0 fire indefinitely once any resources are ever detected, and increase() stops firing after its time window even if the same resources keep getting flagged. Requested gauge-style metrics that reflect the current count from the latest scan, which lets you write real “something needs attention right now” alerts.