The one vendor platform on my open-source stack: Spectro Cloud Palette

How I heard about Palette
Scott Rosenberg has been a recurring guest on Viktor Farcic’s live AMAs, and every few sessions he’d drop a Spectro Cloud mention with visible enthusiasm. “This is the platform I actually trust in production,” give or take. Viktor, who is not easy to impress, would nod along. I kept filing the name under “look at this eventually” while quietly keeping Kubespray running in my homelab.
That also pushed against a default of mine. I self-host most of the stack and lean open-source wherever a credible alternative exists; vendor platforms, and SaaS especially, don’t earn a seat here easily. Spectro Cloud Palette is one of the very short list of exceptions.
So when I spotted the Spectro Cloud booth at KubeCon London 2025, I had to stop by, find out more, and get a demo.
The booth
I ended up stopping by twice and had proper conversations with Nitasha Dhanjal, Anton Smith, and Kevin Reeuwijk.
Kevin proposed a never-expiring trial so I could run Palette at home at my own pace. What really sold me was that both he and Anton mentioned they run Spectro on their own homelabs; if the people working on it enjoy running it in their personal setups, I had to try it.
The demo at the booth was the thing that pushed me over. I liked it enough on the spot that I took Kevin up on the trial, and I have been running on it ever since. Over the year that followed, it quietly became one of my favorite non-open-source tools on the stack, which is about the highest compliment I give a vendor product.
What I was running away from
For years my homelab clusters were Kubespray installs. Kubespray is a capable Ansible-based installer, and in the beginning it was everything I needed. The problem crept in around the third or fourth upgrade: every customization I’d made (extra kubeadm args, tweaked addon versions, inventory overrides, a couple of patched roles) lived as a personal diff I had to re-port onto every new upstream release. Upgrading meant reading Kubespray’s release notes with a highlighter, diffing my fork against upstream, and praying I hadn’t forgotten one of my own changes. Miss one, and the next cluster reinstall would silently ship without a customization I’d been relying on for months.
Kubespray does support day-2: there are playbooks for cluster upgrades, scaling, and reapplying config. But there’s no controller, nothing reconciles until I run a playbook myself, and every upgrade still landed on top of the fork-maintenance pain above: re-port my diffs, re-run, pray. What I wanted was a declarative blueprint reconciled by something other than me remembering to do it, one I could version, upgrade in place, and share across blue and green. Palette cluster profiles are exactly that.
What Palette actually is
Before going further, the one-sentence framing that made Palette click for me: a cluster is a versioned profile, not a one-shot install. A Cluster Profile is a declarative blueprint covering the full stack (OS, Kubernetes, CNI, CSI, add-ons), kept in sync with every cluster that uses it via an hourly reconciliation loop. Upgrade the profile, every cluster follows. That’s closer to how GitOps tools treat Kubernetes apps, and it’s the thing I’d been missing without knowing the shape of it.
Two things follow from that design and matter for a homelab:
- No lock-in on OS or K8s distro. You choose the pack. I run edge-native BYOI with my own Debian image and upstream kubeadm.
- Local, self-healing clusters. Palette’s architecture is decentralized: each cluster reconciles its own profile locally, so it keeps running if the management plane is unreachable. That’s obviously aimed at air-gapped edge deployments.
What else Palette does
I run Palette through the edge-native flow on Proxmox VMs. That’s a narrow corner of what the product covers. For anyone considering it, the breadth matters:
- Cluster API at the core. Palette is a CAPI-powered platform: every cluster it provisions, across any environment, is a managed CAPI cluster under the hood. Spectro Cloud authors and upstreams several CAPI providers, including the Canonical MAAS one.
- Cloud providers. Native provisioning on AWS, Azure, GCP (full-stack or managed, so EKS / AKS / GKE are first-class), with profiles the same shape as mine.
- Data centers. VMware vSphere, Nutanix, Apache CloudStack, OpenStack.
- Bare metal. Canonical MAAS and metal3. The MAAS integration in particular is deep enough that Palette is probably the reference answer for anyone running MAAS as their provisioning substrate.
- Edge. Kairos-based immutable OS, 2-node HA, zero-downtime OTA updates, low-touch device enrolment. This is the flavour I’m adjacent to: I run edge-native BYOI with my own Debian image, not the Kairos variant.
- Virtual clusters via vcluster integration, for tenant isolation on shared physical clusters.
- Virtual Machine Orchestrator for running VMs and containers from the same platform (via KubeVirt under the hood). This one’s on my personal want-list: eventually move my existing VMs into KubeVirt, retire Proxmox, and run everything on bare-metal k3s.
- Import mode to bring existing clusters under management without rebuild.
Easy to start, deep when you want it
This is the thing I most want to land about Palette, because it’s what flipped me from “vendor-skeptical” to “fine, fine, I’ll use this one”: you can drive it as a next-next-finish installer or as a power-user platform, and the UI makes both paths first-class.
Day one, I built a working cluster profile in roughly one afternoon without touching a single values file: pick a BYOI OS pack, pick a Kubernetes pack (edge-k8s for my setup), pick a CNI (Cilium), add a manifest to delete kube-proxy because Cilium replaces it, register the edge hosts, deploy. That’s it. If someone wanted the lazy path, they genuinely could stop here and have a real cluster. Palette even draws your profile as a tidy stack so you can see the whole thing at a glance:
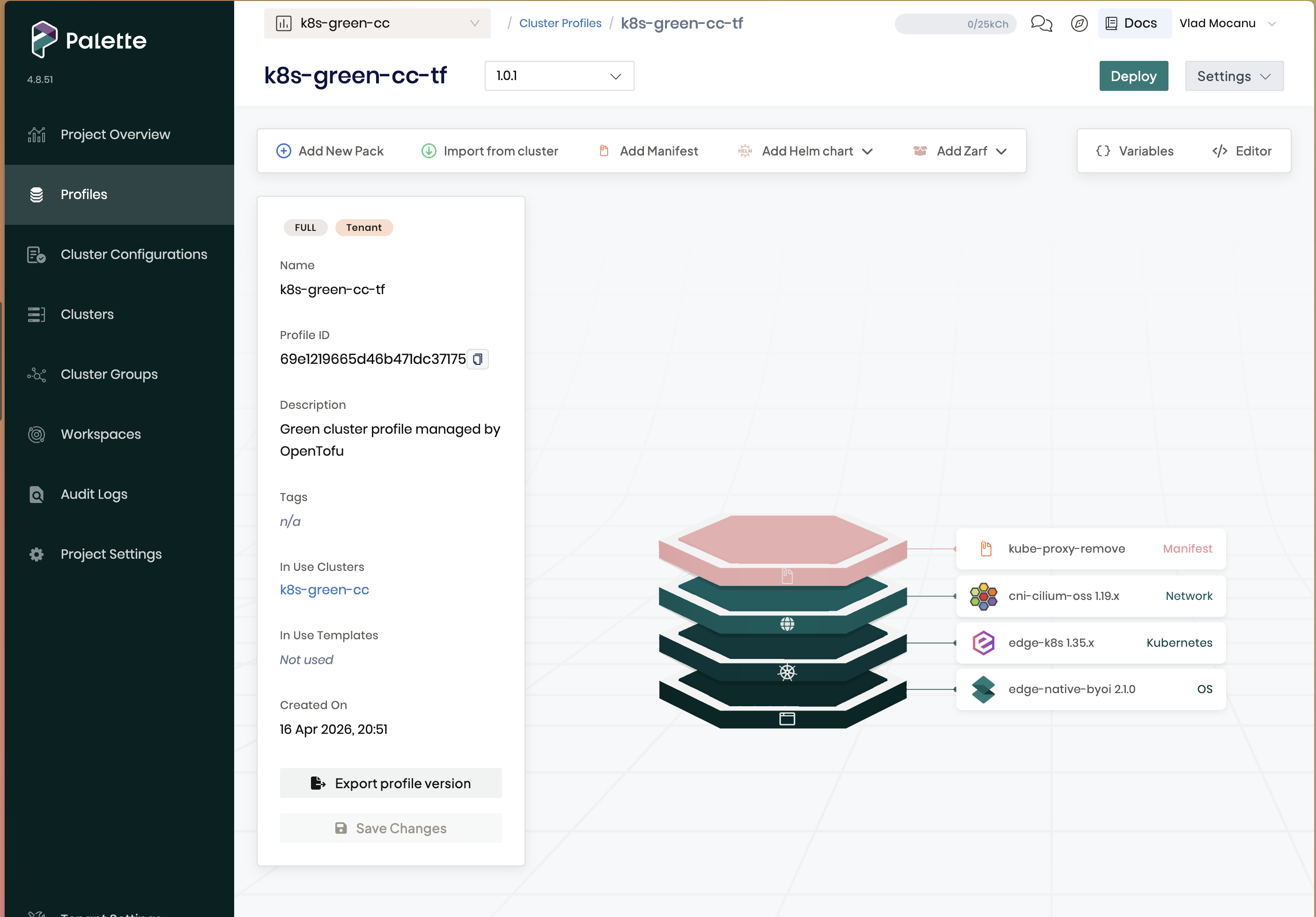
That’s the entire “easy” path: four layers, defaults on every one of them, a green Deploy button in the corner.
Day two was the other surprise. The same UI that hands you defaults also opens up the full upstream values file for every pack, with a Readme, a Values YAML, and Manifests tab visible at once. And a prominent “Use defaults” button to back out again:
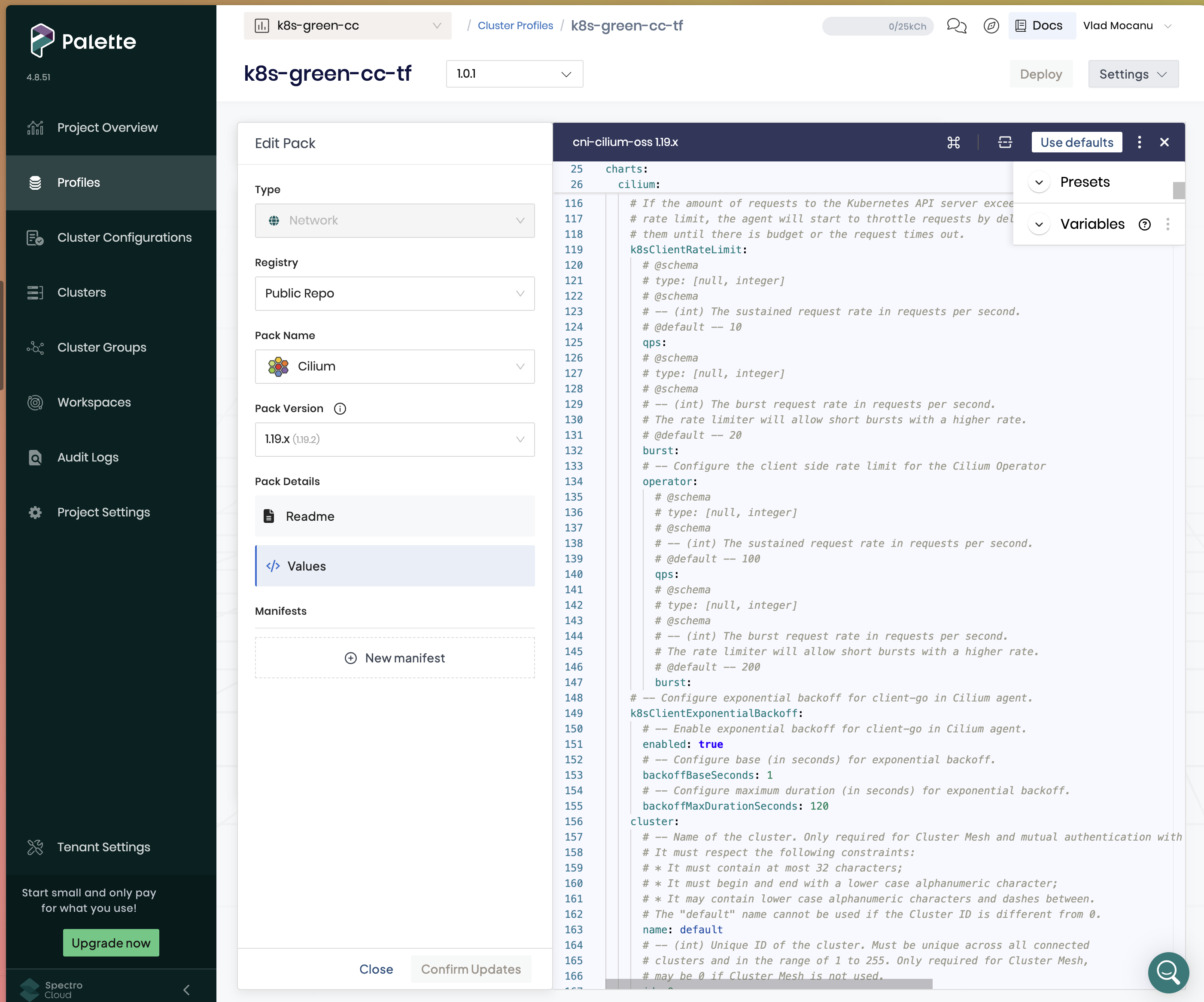
That little “Use defaults” button next to the raw YAML is the whole product philosophy compressed into one UI affordance. You don’t have to know anything about Cilium’s 500-line values file to stand up a cluster. When you do want to know, the file is right there, unabridged, with Presets and Variables helpers sitting next to it for the bits you’d otherwise dig for in Helm docs.
This matches how I like to run things. My default posture is stay as close to vanilla as possible, on every layer: upstream kubeadm, upstream Cilium, upstream Debian, boring defaults everywhere. Palette’s Pack Registry is exactly that, a curated library of community packs with sensible, vanilla-shaped defaults I consume as-is. When I do need to deviate (Cilium with kubeProxyReplacement: true, kubeadm with a custom pod subnet, listen-metrics on etcd so Prometheus can scrape it), I don’t fork the pack or copy its 500-line values file into my repo. I apply narrow, anchored overrides on top of the registry default. The profile is the list of deviations, not the list of everything. That’s the design I’d been trying and failing to get out of a Helm umbrella chart for years.
Beyond the UI, there are four ways to drive Palette programmatically (same next-next-finish-or-power-user spectrum, just headless):
- REST API with an
ApiKeyheader - Official Go SDK
- Terraform provider
- Crossplane provider (community, auto-generated from the TF provider via Upjet)
I use the Terraform provider and plan to stay there. The Crossplane provider is well-maintained, and I run Crossplane heavily for workloads, but cluster provisioning is one place I want a deliberate plan-then-apply boundary rather than a continuous reconciliation loop.
My setup: two edge-native clusters, blue and green
Two edge-native clusters, blue and green, so I can reinstall one while the other serves traffic. Each is a cluster profile with four packs:
| Pack | Purpose |
|---|---|
edge-native-byoi | OS layer (Bring Your Own Image) |
edge-k8s | Kubernetes itself (kubeadm config) |
cni-cilium-oss | Cilium CNI with kubeProxyReplacement: true |
kube-proxy-remove | manifest that deletes the kube-proxy DaemonSet |
Blue and green each pin their own pack versions so I can upgrade one without touching the other. Blue sits on k8s 1.33 + Cilium 1.17; green runs newer on purpose (1.35 + 1.19). The upgrade path becomes trivial: bump the version on the inactive color, re-provision, cut over.
Provisioning a cluster end-to-end is three pieces of automation, in order:
- Terraform (Proxmox provider) stands up the VMs. Per color, 3 control-plane and 3 worker VMs, cloned from golden-image templates on each of the 3 Proxmox nodes. Separate repo, separate state, separate lifecycle from the cluster profiles.
- Ansible runs against the fresh VMs to do OS-level prep and install the Palette edge agent. Disables IPv6, configures containerd, installs the agent, restarts. Once the agent registers, the VMs show up in the Palette tenant as available edge hosts.
- Terraform (spectrocloud provider) defines the cluster profiles and creates the cluster resource that consumes those edge hosts.
tofu applyreconciles the profile against the Palette API, and Palette reconciles the cluster against the registered edge hosts.
The full blue/green cutover, including driving the Palette API through its rate-limits, is orchestrated by a Textual TUI I built that I now also treat as my disaster-recovery rehearsal tool.
Every layer of my homelab cluster is declarative, pinned, reviewable, and reproducible per color.
The “AI magic” moment
I originally built the profiles in the web UI, which was fine for one cluster and bearable for two. But I was also building a cutover TUI that needed the full profile lifecycle automated, which meant the profiles themselves had to leave the UI and move into Terraform so diffs, reviews, and upgrades all flowed through git.
This is where Claude earned its keep. I already had:
- Two running cluster profiles in Palette, built via the UI
- A detailed wiki runbook where I’d documented every step and every customization I’d applied to pack values
I pointed Claude at both: “dump the running profiles via the API, read this wiki page, turn them into clean Terraform with blue and green as a for_each map.”
What came back was genuinely uncanny. Every pack, every value override, every per-color subnet swap, accurate on the first pass. The work that would have taken me two careful evenings of diffing UI screens against pack defaults and writing HCL by hand was done in the time it took me to make a coffee. That’s the closest I’ve come in a while to the “this tool is AI magic” feeling, and I’ve been using Claude Code for a while.
Was the first cut perfect? No. It inlined full pack values as giant heredocs, which pushed the file past 1200 lines and made diffs unreadable. I pushed back. I wanted registry defaults plus targeted replace() chains, not full value blobs checked into source. We iterated. I fought Claude a few times over style. But the final shape is exactly what I’d have written by hand if I’d had infinite patience.
Here’s the core of the profile, lifted from the repo (trimmed for clarity):
resource "spectrocloud_cluster_profile" "cluster" {
for_each = var.colors
name = "k8s-${each.key}-cc-tf"
cloud = "edge-native"
type = "cluster"
version = each.value.profile_version
pack {
name = "edge-native-byoi"
tag = data.spectrocloud_pack.edge_native_byoi.version
type = "spectro"
registry_uid = data.spectrocloud_registry.spectro_registry.id
uid = data.spectrocloud_pack.edge_native_byoi.id
values = data.spectrocloud_pack.edge_native_byoi.values
}
pack {
name = "edge-k8s"
values = local.edge_k8s_values[each.key] # registry defaults + replace() chain
# ...
}
pack {
name = "cni-cilium-oss"
values = local.cilium_values[each.key] # registry defaults + replace() chain
# ...
}
pack {
name = "kube-proxy-remove"
type = "manifest"
manifest {
name = "kube-proxy-remove"
content = file("${path.module}/manifests/kube-proxy-remove.yaml")
}
}
}The replace()-chain pattern is my favorite trick here. Instead of copying an entire 500-line values file into source and watching it rot every time upstream bumps, I fetch the registry default at plan time and patch only the anchors I care about:
cilium_values = {
for color, pack in data.spectrocloud_pack.cni_cilium_oss : color => replace(
replace(pack.values,
"kubeProxyReplacement: \"false\"", "kubeProxyReplacement: \"true\""),
"tunnelProtocol: \"\"", "tunnelProtocol: geneve"
)
}The obvious risk is anchor drift: upstream renames kubeProxyReplacement: "false" to something slightly different, my replace() silently becomes a no-op, and the cluster ships without the customization. I guard against that with precondition blocks that fail the plan loudly if any anchor disappears:
lifecycle {
precondition {
condition = alltrue([
for anchor in local.cilium_required_anchors :
strcontains(data.spectrocloud_pack.cni_cilium_oss[each.key].values, anchor)
])
error_message = "cilium anchor drift, update locals.tf"
}
}So a pack version bump either keeps working or tells me exactly which anchor to re-check. No silent regressions, no midnight surprises. This is the exact inverse of the Kubespray pain I opened the post with: instead of me re-porting my customizations onto every new upstream, upstream ships and tofu plan tells me whether my overrides still make sense. Kubespray made me the QA; Palette lets the plan do it.
The OSS alternative I’d try
If I ever wanted to look at something else besides Spectro, I wouldn’t go back to Kubespray. I’d reach for a cluster-lifecycle stack built around Cluster API plus Sveltos for the add-on layer.
Sveltos is the work of Gianluca Mardente, and it does for add-ons roughly what CAPI does for clusters: declarative, multi-cluster, templated deployments of Helm charts, kustomize overlays, and raw manifests across a fleet, with solid multi-tenancy. Pair it with a CAPI provider for your substrate (CAPMOX for Proxmox, CAPM3 for metal3, CAPA for AWS, and so on) and a CNI like Cilium, and you end up with roughly the shape of a Palette cluster profile, assembled from open-source parts.
Eleni Grosdouli has written a walkthrough of that exact stack on Proxmox: RKE2 as the management cluster, CAPMOX provisioning workload clusters, Cilium for networking, and Sveltos driving add-ons across the fleet via templated manifests. It reads like the OSS-native counterpart to what I do with Palette.
I have not used Sveltos myself, so this is a plan on paper, not a validated path. But the primitives are all pieces I respect, and I met both Gianluca and Eleni at Cloud Native Rejekts / KubeCon Amsterdam 2026; they are the kind of deeply passionate, deeply technical people whose work I tend to bet on sight unseen.
For now, I’m enjoying Spectro and it works perfectly for my homelab stack, so I’m not looking at alternatives. But Sveltos + CAPI is where I’d start if that ever changed.
Closing note
Spectro Cloud has quietly become one of those pieces of the stack I stopped worrying about. Defaults when I want them, full control when I need it. A real API, a real Terraform provider, a real Crossplane provider. I can operate it from the UI, the CLI, the API, or a Kubernetes CRD, and I pick whichever tool fits the task.
For the record, the entire list of non-open-source tools I run (at the moment of writing) is three: Spectro Cloud Palette for cluster provisioning, Kasten K10 for backups, and Tailscale as an overlay network and exit node. That Palette earned a seat on an otherwise aggressively open-source stack (alongside two tools I also took years to let in) is, in my book, the strongest compliment I have.